NVIDIA GB300 NVL72 Sets New Standards in AI Inference Performance
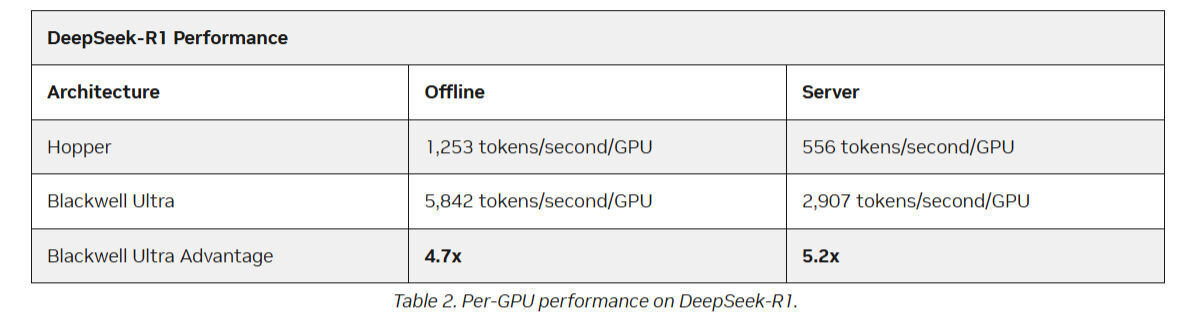
Inference performance is a critical factor in the efficiency and economics of AI infrastructure. High-throughput AI systems can process more tokens at greater speeds, directly increasing revenue, reducing total cost of ownership (TCO), and boosting overall productivity. In less than six months since its introduction at NVIDIA GTC, the NVIDIA GB300 NVL72 rack-scale system—powered by the advanced NVIDIA Blackwell Ultra architecture—has established new records on the latest MLPerf Inference v5.1 benchmarks. Notably, it delivers up to 1.4 times greater DeepSeek-R1 inference throughput compared to NVIDIA Blackwell-based GB200 NVL72 systems.
Blackwell Ultra Architecture: Advancing AI Compute
The Blackwell Ultra architecture builds on the foundation of the original Blackwell design, offering significant enhancements for AI workloads. It features 1.5 times more NVFP4 AI compute and doubles the attention-layer acceleration compared to its predecessor. Each GPU is equipped with up to 288 GB of HBM3e memory, supporting demanding AI models and large-scale inference tasks.
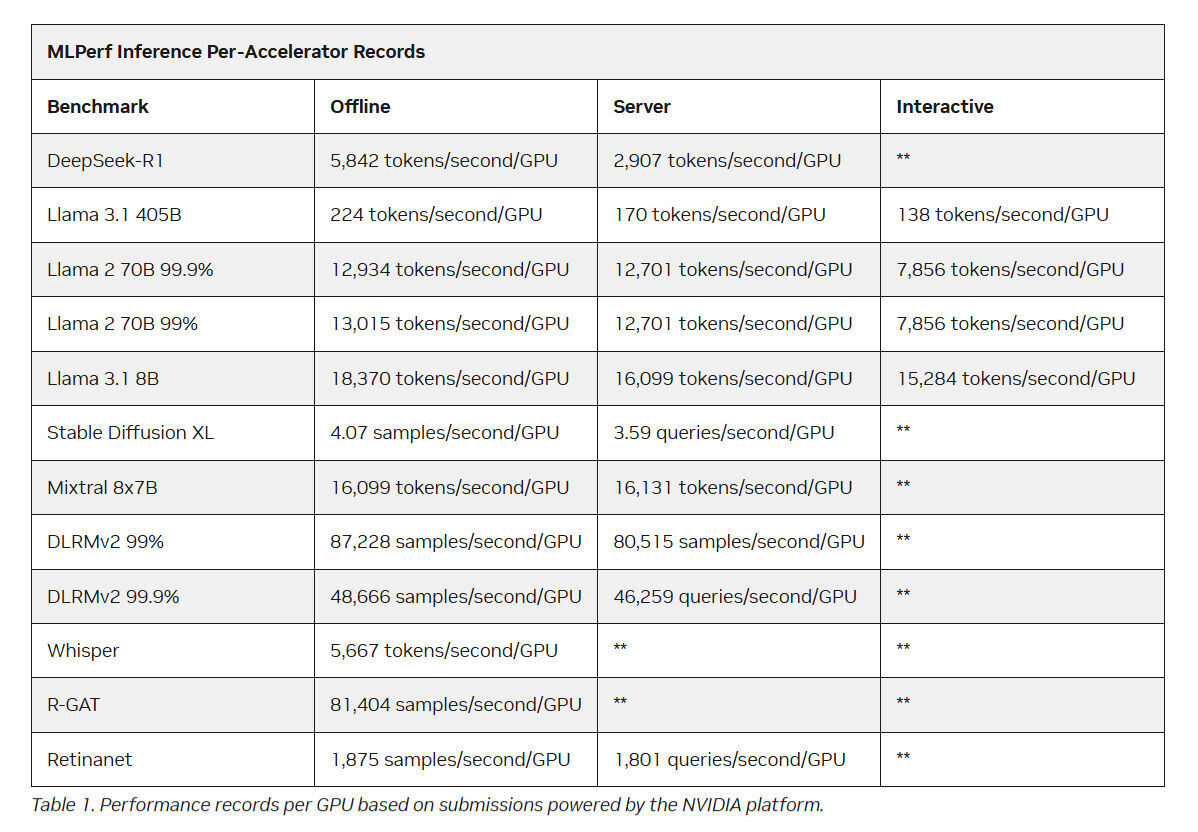
The NVIDIA platform also achieved record-breaking results across all new data center benchmarks introduced in MLPerf Inference v5.1, including DeepSeek-R1, Llama 3.1 405B Interactive, Llama 3.1 8B, and Whisper. It continues to hold per-GPU records on every MLPerf data center benchmark, underscoring its leadership in AI inference performance.
Full-Stack Co-Design and NVFP4 Optimization
Achieving these benchmark results relies on a full-stack co-design approach. Both Blackwell and Blackwell Ultra architectures incorporate hardware acceleration for the NVFP4 data format—a 4-bit floating point format developed by NVIDIA. NVFP4 offers improved accuracy over other FP4 formats and delivers results comparable to higher-precision alternatives.
Using the NVIDIA TensorRT Model Optimizer, models such as DeepSeek-R1, Llama 3.1 405B, Llama 2 70B, and Llama 3.1 8B were quantized to NVFP4. Combined with the open-source NVIDIA TensorRT-LLM library, this optimization enabled the Blackwell platforms to achieve higher performance while maintaining strict accuracy standards in MLPerf submissions.
Innovative Techniques for Large Language Model Inference
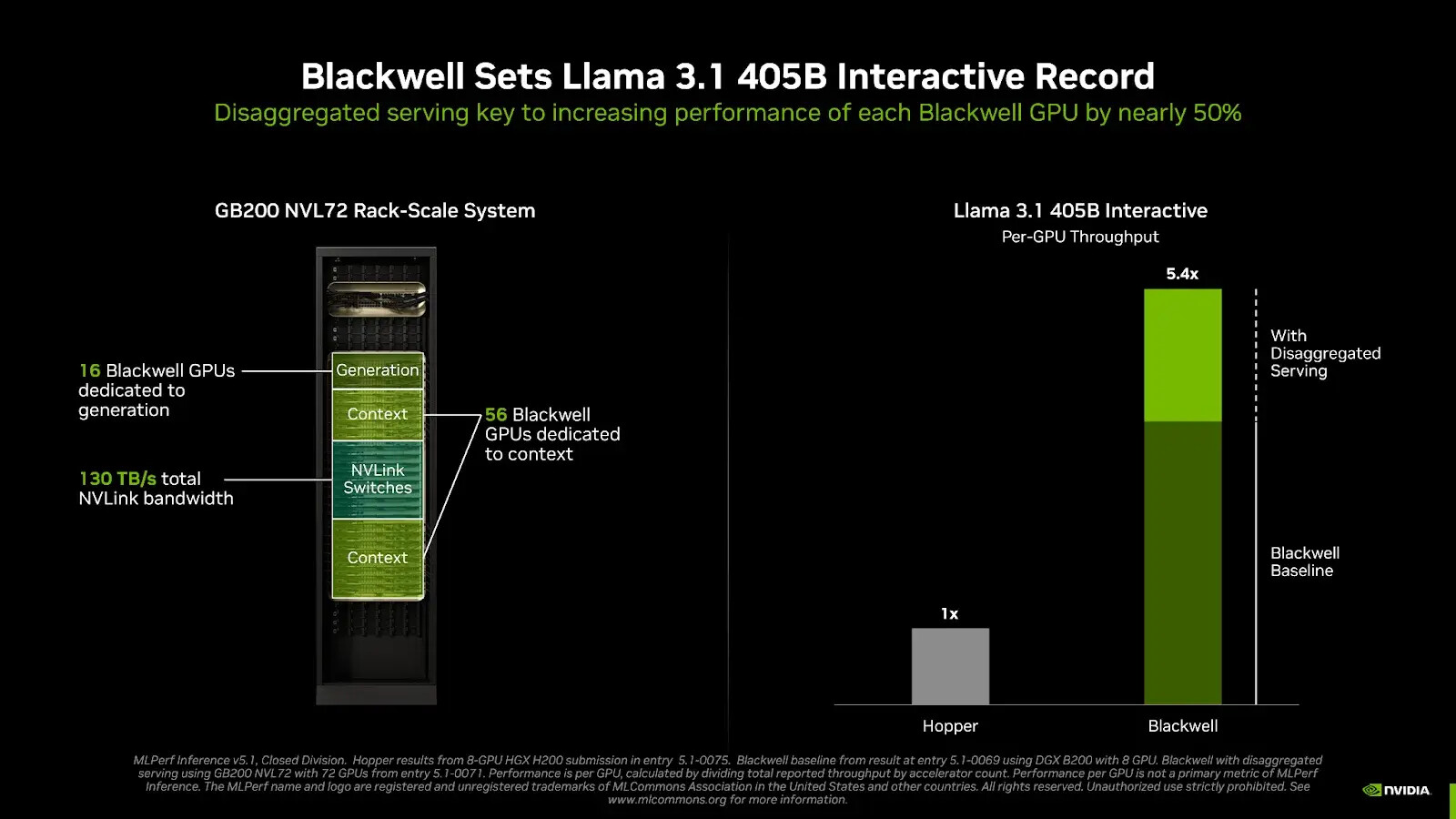
Large language model (LLM) inference involves two distinct workloads: context processing, which handles user input to generate the first output token, and generation, which produces subsequent tokens. NVIDIA employs a technique called disaggregated serving, which separates context and generation tasks to optimize each independently. This approach was instrumental in achieving record-setting performance on the Llama 3.1 405B Interactive benchmark, resulting in nearly a 50% increase in performance per GPU with GB200 NVL72 systems compared to traditional serving methods on NVIDIA DGX B200 servers.
This MLPerf round also marked NVIDIA’s first submissions using the NVIDIA Dynamo inference framework, further expanding its software capabilities for AI inference.
Industry Collaboration and Broad Availability
NVIDIA’s ecosystem partners—including leading cloud service providers and server manufacturers such as Azure, Broadcom, Cisco, CoreWeave, Dell Technologies, Giga Computing, HPE, Lambda, Lenovo, Nebius, Oracle, Quanta Cloud Technology, Supermicro, and the University of Florida—submitted strong results using the NVIDIA Blackwell and Hopper platforms.
The industry-leading inference performance of the NVIDIA AI platform is now accessible through major cloud providers and server vendors. This enables organizations to deploy advanced AI applications with lower TCO and improved return on investment.