NVIDIA Unveils Rubin CPX: A Specialized GPU for Massive-Context AI Models
At the recent AI Infra Summit, NVIDIA introduced the Rubin CPX GPU, a purpose-built accelerator designed to meet the demands of large-context artificial intelligence models. As part of the forthcoming Rubin GPU family, Rubin CPX stands out with its monolithic die architecture, delivering an impressive 30 PetaFLOPS of NVFP4 compute performance and equipped with 128 GB of next-generation GDDR7 memory.
Monolithic Die Design for Enhanced AI Performance
Unlike the dual-GPU packages found in NVIDIA’s current Blackwell and Blackwell Ultra architectures, as well as the rest of the Rubin lineup, Rubin CPX adopts a single-die approach. This design shift addresses computational bottlenecks in scenarios where AI models must process millions of tokens simultaneously—an increasingly common requirement for advanced applications such as comprehensive codebase analysis and long-form video content processing.
The monolithic die not only simplifies manufacturing but also maintains high computational density, making it a cost-effective solution for large-scale AI inference tasks. While NVIDIA has not disclosed the exact memory bandwidth, estimates suggest that a 512-bit interface paired with 30 Gbps GDDR7 memory could achieve up to 1.8 TB/s throughput.
Integrated Video Processing and Accelerated Attention Mechanisms
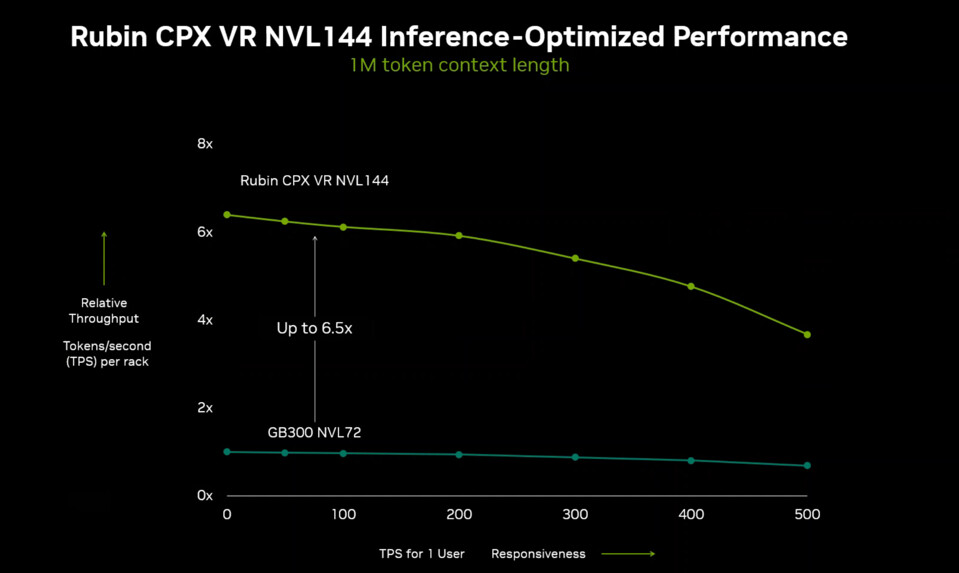
Rubin CPX features four NVENC and four NVDEC video encoders directly on-chip, enabling efficient multimedia workflows without the need for external processing. Performance benchmarks indicate that Rubin CPX delivers three times the attention processing speed compared to NVIDIA’s current flagship, the GB300 Blackwell Ultra accelerator. This leap in performance is particularly significant for AI models that require rapid context prefill and token processing across extensive datasets.
Hybrid Platform and Next-Generation Data Center Integration
NVIDIA plans to deploy Rubin CPX within the Vera Rubin NVL144 CPX platform, which combines standard Rubin GPUs with the specialized CPX variant. This hybrid architecture is engineered to deliver up to 8 ExaFLOPS of aggregate compute power and 1.7 PB/s of memory bandwidth per rack. The upcoming “Kyber” rack will feature advanced ConnectX-9 network adapters supporting 1600G networking, Spectrum6 switches with 102.4T throughput, and co-packaged optics for high-speed data transfer. The Rubin CPX is scheduled for release in late 2026, following the main Rubin GPU launch earlier that year.
Optimized for Evolving AI Inference Workloads
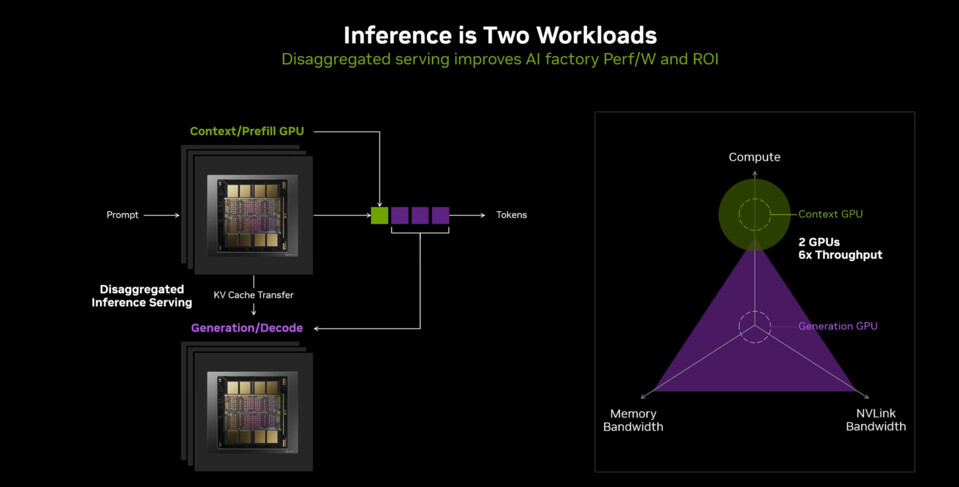
Rubin CPX is positioned as a unique solution within the Rubin family, specifically engineered to address the complexities of inferencing in next-generation AI systems. As AI models evolve from basic text generation to sophisticated reasoning agents, inference workloads are increasingly divided between compute-intensive context processing and memory bandwidth-dependent token generation. Rubin CPX’s architecture is tailored to excel in both areas, supporting context prefill operations for enterprise chatbot sessions with up to 256,000 tokens and code analysis tasks spanning over 100,000 lines.
This level of specialization is essential as AI systems transition toward multistep reasoning and persistent memory across extended interactions. By delivering hardware optimized for these advanced requirements, NVIDIA aims to provide developers with a seamless and efficient platform for building the next generation of AI applications.